What's in a loop?
Strip away the framework and the marketing, and every agent is a loop. Here's what's actually in one.

Every agent I’ve ever built is a loop wearing different clothes. Strip away the framework, the model, the marketing, and what’s left is something that observes, decides, acts, and then looks again at what it changed. The whole field is an argument about what goes in each of those steps. So when people ask what an agent is, I’ve stopped reaching for a definition and started drawing a circle.
This is a piece about that circle: where it came from, what sits around it, the shapes it takes, and the one version of it, borrowed from a fighter pilot, that I’d actually design around.
The oldest idea in the field
The loop predates the word “agent” by decades. Norbert Wiener’s cybernetics in the 1940s was about exactly one thing: feedback. A system senses the world, compares it to a goal, acts to close the gap, and senses again. A thermostat is the canonical example and it is, technically, an agent. It perceives temperature, decides against a setpoint, and acts on a furnace. A dumb one, with a fixed policy, but the structure is all there.
By the time Russell and Norvig wrote the textbook in the 1990s, the definition had hardened into something you’ve probably seen: an agent is anything that perceives its environment through sensors and acts on it through actuators. Perception in, action out, repeat. Reinforcement learning drew the same picture and made it the whole game. An agent and an environment pass observations and actions back and forth, the agent learning a policy that makes the loop pay off over time.
Then language models walked into the decide step. ReAct and the agent loops that followed kept the exact same shape (assemble context, reason, pick an action, execute it, observe the result, feed it back) and swapped the policy for a model that can read and write natural language. That’s the entire novelty. Not a new structure. A new thing sitting in an old seat.
The loop is ancient and settled. What changed is what you can now afford to put in one of its corners, and what it takes to feed that corner well.
The loop and the harness
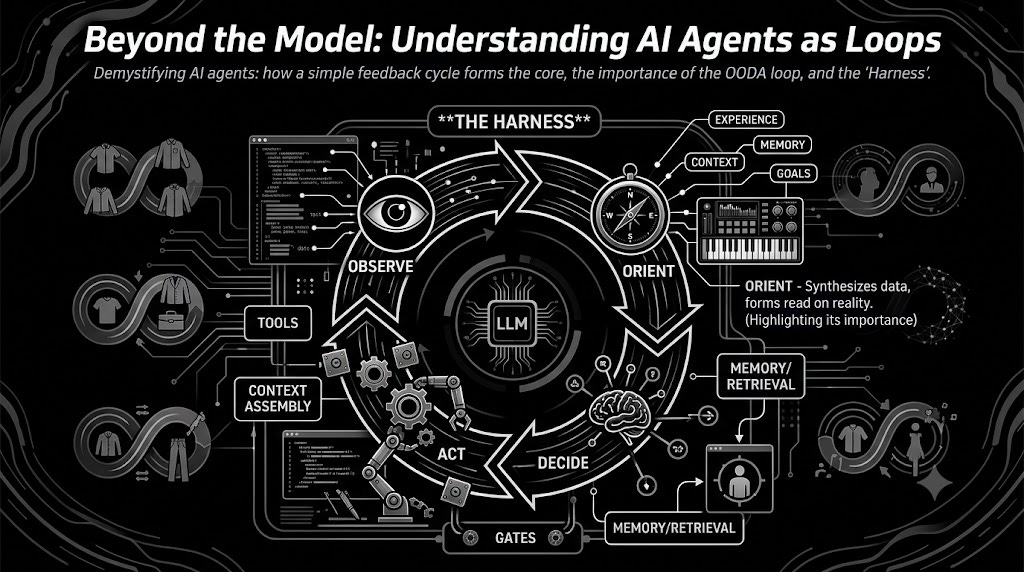
The loop is the engine. The harness is everything bolted around it.
The model only sees what the harness lets it observe and can only do what the harness lets it act on. Tools are the sensors and the actuators. Memory is what survives between turns. Context assembly is the thing that decides, every single iteration, what the model gets to look at before it reasons. Gates are where the loop is allowed to touch the real world and where it has to stop and ask. None of that is the model. All of it determines whether the model is useful.
So most of building an agent is building the harness, not picking the model. I’ve watched a capable model fail because it couldn’t see the thing it needed, and a smaller one succeed because the harness put the right three files in front of it at the right moment. The model is the part everyone talks about. The harness is the part that decides whether the loop closes or spins.
The loop has shapes
Once you start seeing loops, you notice they aren’t all the same.
The control loop is the thermostat: a fixed policy, no learning, fast and reliable inside its lane and useless outside it. Most of production software is control loops, and that’s correct. When a switch statement does the job, you don’t put a model in the seat.
The agent loop is the control loop with a model in the decide step. It trades determinism for range. It can handle inputs you didn’t enumerate, and in exchange it can be wrong in ways you didn’t enumerate either.
The reason-act loop (ReAct and its descendants) splits “decide” into thinking and doing, and crucially adds observe the result of my own action as a first-class step. That observation is what separates an agent from a very long prompt. Without it, the model is guessing into the void. With it, the loop can correct.
Then there are the loops inside the loop. A sampling loop runs the same step several times and judges the spread. I built one of these for judged self-consistency on a single model, and the lesson was that the loop, not the model count, was doing the work. A multi-agent system is loops nested in loops: an orchestrator’s loop dispatches a task, and the agent that receives it runs its own loop to completion before the outer one continues. And around all of it is the human loop, where a person on the merge button is a gate inside the largest loop in the system, the one that decides whether what the machine produced should actually ship.
Naming the shape matters because it tells you what to optimize. A control loop wants reliability. An agent loop wants better orientation. A sampling loop wants a good judge. A multi-agent loop wants a clean contract between the loops. Pick the wrong optimization and you’re tuning a part that isn’t the bottleneck.
The loop that’s about winning
The most useful version of the loop didn’t come from AI at all. It came from John Boyd, a US Air Force colonel who, in the early 1970s, was trying to explain why American pilots in Korea won dogfights they arguably shouldn’t have. His answer was a loop: Observe, Orient, Decide, Act. OODA.
Most people who cite it get it wrong in two ways. First, they draw it as a tidy circle, when Boyd’s real diagram is a tangle of feedback paths with one stage doing most of the work. Second, they think it’s about speed. It isn’t, quite. It’s about tempo: cycling through your loop faster and more relevantly than the thing you’re competing against, until you’re acting on a picture of the world it hasn’t caught up to yet. Boyd called it getting inside the opponent’s loop.
And the stage doing the work is Orient. Observe just gathers raw input. Decide and Act are almost mechanical once the first two are right. Orient is where you take what you observed and run it against everything you already are (your experience, your model of the situation, your context) and turn data into a read on what’s actually happening. Boyd thought orientation was the whole ballgame, and anyone who has debugged an agent knows he was right. The model rarely fails at Decide or Act. It fails because it was oriented wrong: it was looking at a stale file, missing the one constraint that mattered, carrying context from a task that ended an hour ago. Bad orientation, confident action.
That reframes the entire job. When I work on an agent, I am almost never improving its ability to decide or act. I’m improving Orient: what it observes, how that gets synthesized, what it remembers, how I measure whether its read of the situation matches reality. Context engineering, memory, evaluation are all orientation work. The flashy part of an agent is the act. The leverage is one step earlier.
Automating intelligent systems
Here’s how I use this. When I design a system meant to act on its own, I draw its OODA loop and ask, for each stage, two questions: what’s automated, and what’s gated.
Observe is the harness: the tools, the context assembly, the retrieval. Automate it aggressively, because the loop can’t be better than what it sees. Orient is the model plus everything I feed it, and it’s where I spend most of my effort, because it’s where the system is most often wrong and where improvement compounds. Decide is the model’s call, and for a well-oriented loop it’s cheaper and safer than it looks. Act is tool execution, and it’s where I put the gates. The loop runs free right up until it would change something that’s expensive to undo, and there it stops for a human.
That’s the dark-factory model stated as a loop. The agents own a full OODA cycle for producing a mergeable change. They observe the codebase, orient against the task and the conventions, decide on an approach, and act by writing and reviewing it. The human owns a slower, outer loop: not “is this line right,” but “is this loop pointed at the right thing at all.” Two loops at two tempos, and a gate between them.
The goal of the whole arrangement is the thing Boyd was after — tempo. A system worth automating is one that can cycle faster than its problem changes. Get that, and the machine is acting on a current picture of the world while the problem is still catching up. Miss it, and you’ve built something that confidently solves the situation it was in five minutes ago.
That’s what’s in a loop. The model is one corner of it, the corner everyone stares at. Almost everything that decides whether the system works lives in the other three, and in how fast you can get around the circle. Build the harness, obsess over orientation, gate the act, and turn the loop faster than the competition can. The rest is which model you drop into the seat.
If you want to see one wired up, that’s what I build protoAgent for: an open, A2A-native substrate that keeps the boring parts of the loop stable (the agent loop, tool calls, memory, evals, the release pipeline) so forking an agent comes down to which model goes in the seat. Take it, fork it, point it at your own problem: github.com/protoLabsAI/protoAgent.
Threads pulled here: Norbert Wiener’s cybernetics and the feedback loop; Russell & Norvig’s sensors-and-actuators agent; the reinforcement-learning agent and environment loop; ReAct; and John Boyd’s OODA loop. Companion piece: How I build with agents.